![]() Télécharger la version PDF de la fiche
Télécharger la version PDF de la fiche
Présentation de la fiche
À qui s'adresse-t-elle ?
- Responsables de la sécurité des systèmes d'information (RSSI)
- Administrateurs du système d'information
Quand l'utiliser ?
Utiliser cette fiche lorsqu'un incident de type déni de service réseau est détecté ou suspecté contre un ou plusieurs services de votre organisation exposés sur Internet.
À quoi sert-elle ?
L'objectif de cette fiche est de proposer les premières actions d'endiguement ayant pour objectif de circonscrire l'attaque. Elles tenteront de limiter son impact et de donner du temps aux défenseurs pour s’organiser et reprendre l’initiative.
Comment l'utiliser ?
Deux parties principales composent cette fiche :
- La partie Actions d'endiguement par priorités pointe l'ordre chronologique et prioritaire des actions détaillées dans la partie suivante.
- La partie Actions d'endiguement par périmètre et type de déni de service détaille les différentes actions d'endiguement possibles selon le périmètre et le type du déni de service réseau.
Si l'organisation estime avoir besoin d'aide pour réaliser ces actions d'endiguement, elle peut contacter des équipes spécialisées en réponse à incident, qu'elles soient internes ou externes : voir la partie Contacts.
Sommaire
- Prérequis
- Actions d'endiguement par priorités
- Actions d'endiguement par périmètre et type de déni de service
- Suite des actions
- Annexes
Prérequis
Avoir qualifié l'incident
Avoir qualifié que l'incident de type déni de service réseau ne soit pas un incident de production, mais soit bien la conséquence d'un acte malveillant, et avoir évalué sa gravité. Avoir établi les caractéristiques de l'attaque et l'élément défaillant de la chaîne (impact informatique.
Fiche précédente conseillée : Fiche réflexe - Déni de service réseau - Qualification
Les mesures d'endiguement proposées dans cette fiche devront être appliquées en cohérence avec les conclusions de la qualification : le périmètre affecté par l'incident, son impact potentiel sur l'organisation, l'urgence à résoudre la situation, etc.
Avoir les capacités d'administration
S'assurer que les personnes qui mettront en œuvre les actions d'endiguement aient les droits d'administration du système d'information (réseau, système, sécurité opérationnelle) et que les acteurs externes en capacité de faire les actions soient identifiés et puissent être sollicités.
Ouvrir une main courante
Dès le début de l'incident, ouvrir une main courante pour tracer tous les actions et évènements survenus sur le système d'information dans un ordre chronologique.
Chaque ligne de ce document doit représenter une action avec au minimum trois informations :
- La date et l'heure de l’action ou de l'évènement (si estimé nécessaire, ajouter le fuseau horaire UTC)
- Le nom de la personne ayant réalisé cette action, ayant en charge l'action en cours ou en suspens, ou ayant informé sur l'évènement
- La description de l’action ou de l’évènement, incluant les détails de son avancement ainsi que les comptes et machines concernés.
Ce document sera utile pour :
- Réaliser un historique du traitement de l'incident et partager la connaissance
- Piloter la coordination des actions et suivre leur état d'avancement
- Évaluer l'efficacité des actions et leurs potentiels impacts non prévus
Cette main courante doit être éditable et consultable par tous les intervenants. Il est déconseillé de la stocker dans le périmètre sous déni de service, mais peut l'être sur un partage de fichiers en ligne (cloud), intégrée dans le logiciel de gestion d'incident ou le SIEM si l'organisation en possède un, voire être au format papier.
Actions d'endiguement par priorités
Cette partie pointe l'ordre chronologique et prioritaire des actions détaillées dans la partie suivante :
| Actions | Priorité |
|---|---|
| Ordonner vos actions dans le périmètre défini et sélectionner les mesures en fonction des caractéristiques du déni de service (Mesure 1) | P0 |
| Limiter le trafic en amont de l'entité (avec le FAI) (Mesure 2) | P1 |
| Activer le service anti-DDoS externe, si possible (Mesure 4 - Action 4.d) | P1 |
| En cas d'attaque sur les services DNS : agir sur les configurations (Mesure 4 - Action 4.a) | P1 |
| En cas d'attaque sur les applications : activer le CDN (Content Delivery Network) si possible (Mesure 4 - Action 4.b) | P1 |
| Agir dans le périmètre de l’hébergeur (Mesure 3) | P2 |
| Agir sur les composants tiers (Mesure 4 - Action 4.c) | P3 |
| Préserver les traces des journaux d'équipements (Mesure 5) | P4 |
Actions d'endiguement par périmètre et type de déni de service
Cette partie détaille les différentes mesures d'endiguement possibles selon 3 axes thématiques. Chaque mesure est ensuite scindée en actions unitaires :
Les actions présentées dans cette partie sont regroupées par thèmes, et non par priorités ! Pour cela, se référer à la précédente partie Actions d'endiguement par priorités.
Le schéma d'architecture ci-après va servir de base pour illustrer la démarche d'endiguement. Il représente une architecture classique de service exposé sur internet qui devra être ajustée en fonction des conditions spécifiques dans lesquelles l'organisation opère : les variations des équipements d'infrastructure, le choix entre un hébergement sur site ou dans le cloud, etc.
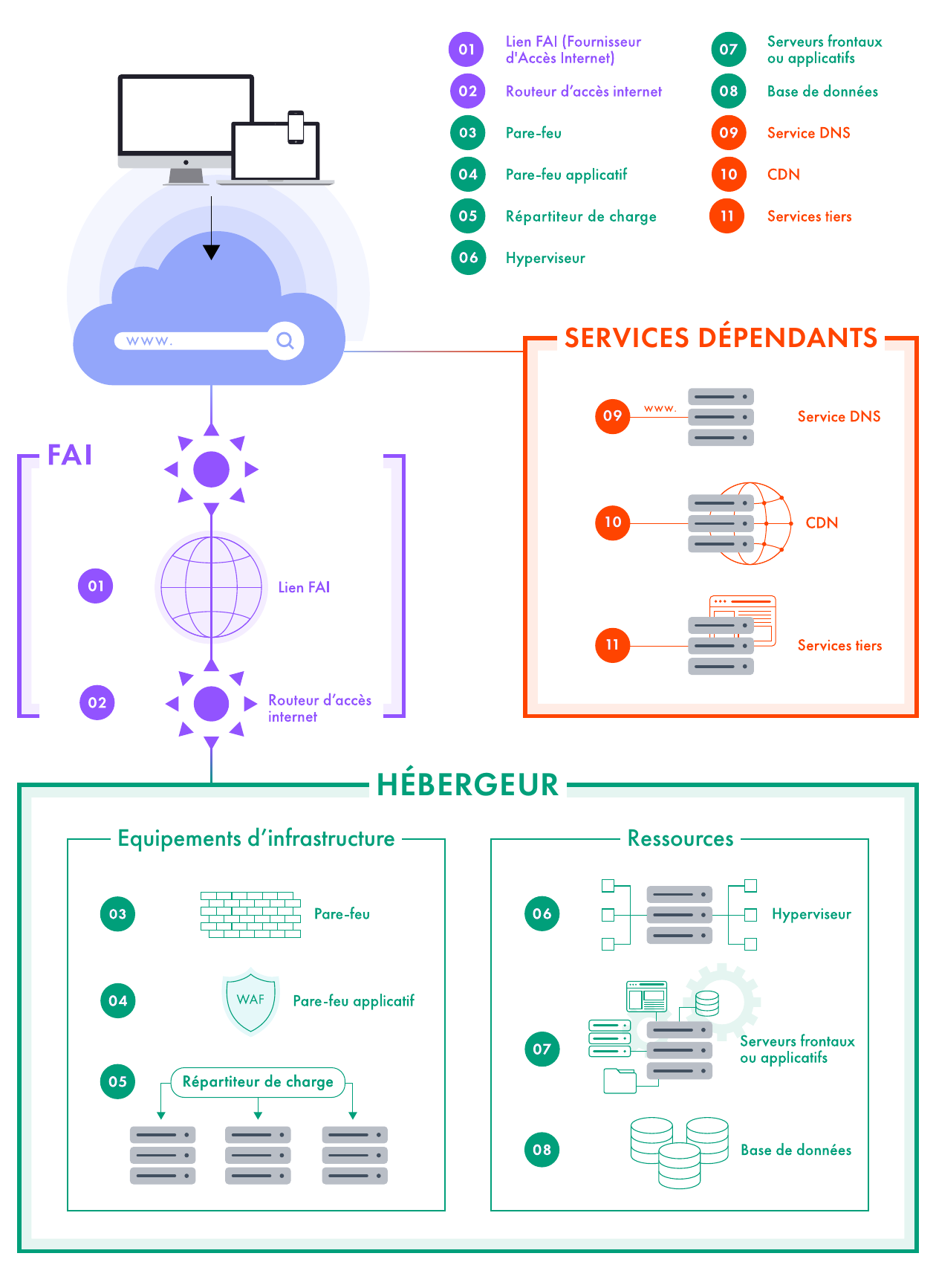
FAI : Fournisseur d'accès internet
Remarque:
Les services dans le périmètre [Services dépendants] peuvent également faire partie du périmètre Hébergeur [Périmètre Hébergeur].
Sélectionner les actions appropriées
Mesure 1 - Ordonner vos actions dans le périmètre défini et sélectionner les mesures en fonction du déni de service
Action 1.a : Déterminer le périmètre et l'ordre des actions d'endiguement
Le traitement de l'endiguement doit :
- Commencer par le ou les éléments en amont du composant défaillant afin de réduire le trafic à destination du composant défaillant
- Se terminer par le ou les composants défaillants afin de réduire la surcharge subie
- Appliquer les actions d'endiguement de façon unitaire afin de juger de leur efficacité et de mesurer les éventuels effets de bord
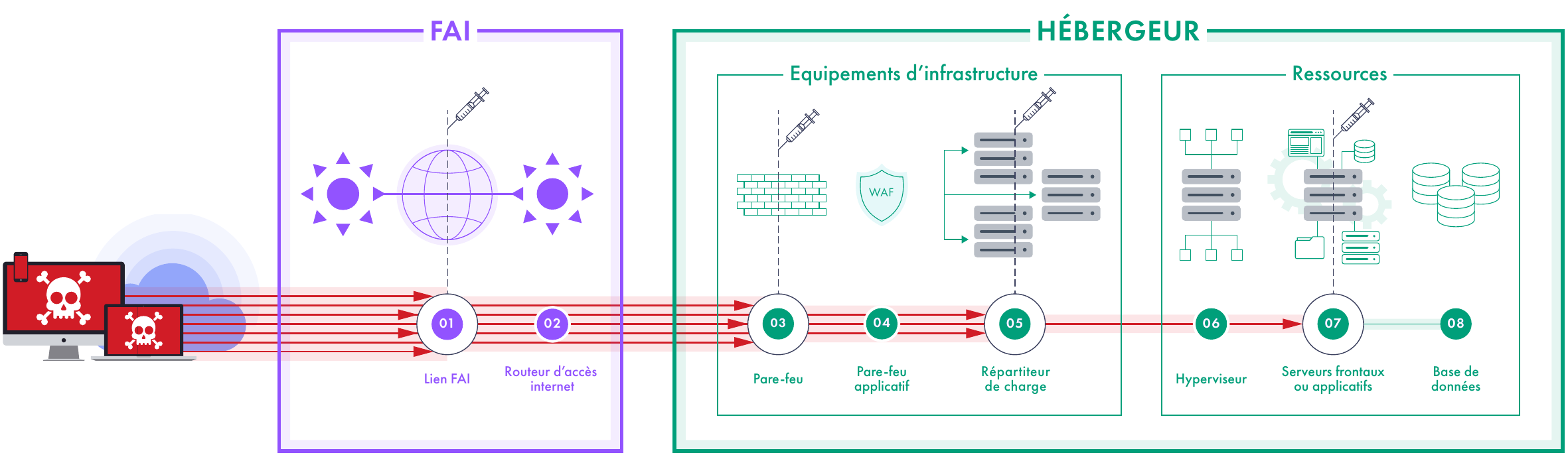
Action 1.b : Sélectionner les actions d'endiguement
Les actions sélectionnées sont à mettre en œuvre en fonction :
- Des caractéristiques du déni de service établies à travers la fiche réflexe : Fiche réflexe - Déni de service réseau - Qualification" (Généralités,
[Déni de service volumétrique],[Déni de service sur les protocoles],[Déni de service sur les applications],[Déni de service sur les services DNS], etc. ) - Du contexte d'infrastructure de l'organisation
Remarques:
- Les actions d'endiguement sont proposées de façon générique et ne constituent pas une liste exhaustive de mesures possibles d'atténuation.
- Avant l'exécution des actions d'endiguement, leurs impacts doivent être évalués au regard des résultats attendus et des conséquences métiers potentielles.
-
Les actions d'activation de services comme un CDN ou un service de filtrage spécifique aux attaques par déni de service (anti-DDoS) supposent que la contractualisation et l'intégration aient déjà été faites ou que la prise en compte du coût, du délai de mise en œuvre et de l'adaptation de l'implémentation avec le système d'information ait été évaluée.
- Le choix de recourir à une solution externalisée comme CDN ou une protection applicative (niveau 7) conduit dans la plupart des cas à déporter la terminaison TLS en fournissant le certificat. L'impact sur la confidentialité des données d'un point de vue métier et réglementaire est donc à mesurer en raison de ce déchiffrement de flux. Cette réflexion s'applique également envers les info-géreurs qui administrent ce type de solution, y compris les solutions internalisées.
- Les choix d'actions d'endiguement peuvent avoir des effets sur la facturation, en particulier dans les environnements Cloud.
Limiter les impacts
Mesure 2 - Limiter le trafic en amont de l'entité (avec le FAI)
Ces actions tentent d'épurer le trafic dans le périmètre du fournisseur d'accès internet (FAI) et limitent les requêtes vers l'infrastructure de l'entité. Ce type d'endiguement s'adresse plus particulièrement lorsqu'un discriminant fort (exemples : IP source, protocole, etc.) a pu être trouvé dans la phase de qualification.
Attention: Il convient de contacter le fournisseur de service, idéalement en amont, afin de connaître les niveaux de services proposés, leurs coûts, le délai de mise en œuvre effectif et l'éventuelle adaptation de l'implémentation avec le système d'information de l'entité.
Action 2.a : Identifier un contact technique de votre FAI
- Contacter le support technique de votre FAI qui peut être en mesure de vous donner de la visibilité et peut vous orienter dans le traitement de votre incident.
Action 2.b : Limiter le trafic en amont de l'entité (avec le FAI)
-
(1) Infrastructure FAI
- Faire bloquer les requêtes à partir des éléments discriminants (ex : IP source, protocole, géolocalisation, etc.) issus de la qualification
- Faire configurer Flowspec sur les routeurs d'infrastructure pour diffuser des règles de traitement du trafic en BGP et spécifier un débit maximal en définissant une valeur à traffic-rate (contrôle de débit - rate-limiting) à partir des éléments discriminants
-
Si les services ciblés ne sont pas essentiels, supprimer temporairement les requêtes (Blackhole ou Remote Triggered Black Hole - RTBH) à destination des IP cibles causant un déni de service effectif sur le service visé par l'attaque
- Parallèlement, rétablir les services indirectement impactés s'ils sont importants
- En cas d'attaque sur le FQDN, un changement d'entrée DNS du service visé peut également rétablir les services indirectement impactés
-
(2) Routeur d'accès internet
- Redémarrer l'équipement (en cas d'absence de fonctionnement)
Attention: Un redémarrage de routeur, selon le modèle, peut prendre plusieurs minutes. Les impacts de cette action sont donc à mesurer.
Action 2.c : Activer le Service anti-DDoS du FAI
- Si disponible, activer ce service
- Mettre à jour les règles (blocage de requêtes) et les seuils (contrôle de débit - rate-limiting) avec les éléments discriminants de la qualification
-
Si disponible, activer des fonctionnalités qui permettront de :
- Bloquer les requêtes qui ont une destination erronée (ex: requête visant un service en spécifiant un port qui n'est pas exposé)
- Bloquer les requêtes par IP source réputée malveillante issue des bases de la Cyber Threat Intelligence (CTI)
- Mettre en place des règles de blocage à partir de critères discriminants basés sur les empreintes JA3/S et JA4 (profilage à partir d'informations collectées lors des échanges SSL/TLS)
- Mettre en place d'autres fonctionnalités du service anti-DDoS
Mesure 3 - Agir dans le périmètre de l’hébergeur
Action 3.a : Activer le service anti-DDoS de l'hébergeur (en amont du pare-feu et du routeur)
- Si disponible, activer ce service
- Mettre à jour les règles (blocage de requêtes) et les seuils (contrôle de débit - rate-limiting) avec les éléments discriminants de la qualification
-
Si disponible, activer des fonctionnalités qui permettront de :
- Bloquer les requêtes qui ont une destination erronée (ex: requête visant un service en spécifiant un port qui n'est pas exposé)
- Bloquer les requêtes par IP source réputée malveillante issue des bases de la Cyber Threat Intelligence (CTI)
- Bloquer les requêtes par reconnaissance de robot (Challenge captcha dynamique ou challenge Javascript - JS)
- Mettre en place de blocage à partir de critères discriminants basés sur les empreintes JA3/S et JA4 (profilage à partir d'information collectée lors des échanges SSL/TLS)
- Mettre en place d'autres fonctionnalités du service anti-DDoS
Action 3.b : Limiter les requêtes sur les équipements d'infrastructure réseau
-
Généralité
-
Réseau d'administration
- Si possible, Marquer le trafic d'administration prioritaire au moyen de la mise en place d'une QoS (Quality of Service) en cas d'indisponibilité du réseau d'administration
-
Réseau d'administration
-
(3) Pare-feu
-
Généralités
- Mettre à jour l'équipement en cas de déni de service lié à des vulnérabilités de la version du firmware
- Ajuster les règles de pare-feu afin de limiter les services et protocoles exposés et rejeter les autres requêtes
- Si possible, mettre en place une politique de blocage des paquets mal formés ou une politique de protection DoS
- Bloquer les requêtes à partir des éléments discriminants (ex : IP source, protocole, géolocalisation, etc.) issus de la qualification
- Bloquer les requêtes par IP source réputée malveillante issue des bases de la Cyber threat Intelligence (CTI)
- Filtrer sur les IP/bloc/AS (Autonomous System)/géolocalisation autorisées à se connecter aux services
-
Si les services ciblés ne sont pas essentiels, supprimer temporairement les requêtes (Blackhole) à destination des IP cibles causant un déni de service effectif sur le service visé par l'attaque
- Parallèlement, rétablir les services indirectement impactés en fonction de leur importance
-
Cas des
[Déni de service volumétrique]-
Appliquer un contrôle de débit (rate limiting). Par exemple, définir des seuils de blocage de requête par IP source en fonction de paramètres comme la bande passante, le nombre de paquets par seconde, le nombre de requêtes applicatives avec des signatures malveillantes
- Assurer une supervision afin d'observer d'éventuels effets de bord
- Appliquer une régulation de flux (traffic shaping) afin de prioriser certains flux
-
Appliquer un contrôle de débit (rate limiting). Par exemple, définir des seuils de blocage de requête par IP source en fonction de paramètres comme la bande passante, le nombre de paquets par seconde, le nombre de requêtes applicatives avec des signatures malveillantes
-
Cas des
[Déni de service sur les protocoles]- Réduire les durées de vie de suivi de connexions
- Limiter le nombre de paquets SYN par seconde par IP source
- Limiter le nombre de paquets SYN par seconde par IP de destination
- S'assurer que la fonctionnalité SYN cookie est activée
- Mettre un seuil sur le nombre de requêtes ICMP par IP source
- Mettre un seuil sur le nombre de requêtes UDP par IP source
-
Généralités
-
(4) Pare-feu applicatif
-
Généralités
- Mettre à jour les signatures d'attaques
- Simplifier la configuration pour décharger les processeurs
-
Cas des
[Déni de service volumétrique]- Appliquer un contrôle de débit (rate limiting) ou une régulation de flux (traffic shaping)
-
Cas des
[Déni de service sur les applications]- Appliquer le blocage des requêtes malveillantes avec des signatures
- Définir des règles précises pour bloquer sur les discriminants de niveau 7 (applicatif) observés lors de la qualification Attention: Ne pas mettre en œuvre cette mesure sur des attaques volumétriques d'ampleur, au risque de surcharger le processeur et causer un nouveau déni de service
- Appliquer une limite de session au niveau des services web
- Utiliser les fonctionnalités de cache
- Bloquer les requêtes par reconnaissance de robot (Challenge captcha dynamique ou challenge Javascript - JS)
- Réduire les durées de vie de suivi de connexions
-
Généralités
-
(5) Répartiteur de charge
- Appliquer un contrôle de débit (rate limiting)
- Réduire les durées de vie de suivi de connexions
Action 3.c : Limiter les requêtes sur les ressources
-
(6) Hyperviseur
-
Optimiser les ressources en cas de saturation
- Répartir la charge (avec la création d'instances par exemple)
- Répartir et/ou allouer les ressources
- Séparer les instances sur des zones géographiques distinctes (sharding)
- Mettre à jour l'hyperviseur
- Migrer les autres machines pour avoir plus de ressources
- Migrer la machine impactée pour relancer les autres services
-
Optimiser les ressources en cas de saturation
-
(7) Serveurs frontaux ou applicatifs
-
Cas du système qui sature
-
Si l'accès au serveur n'est plus possible pour cause de saturation :
- Couper l'accès réseau de production
- Redémarrer le serveur
- Appliquer les optimisations système
- Ré-ouvrir les flux de production
- Allouer d'avantage de ressources à la machine
- Ajuster les seuils système limitants (exemples : Ulimit et systemd sur les environnements Linux)
- Optimiser sur le bas niveau des systèmes d'exploitation (exemples : sysctl sur les environnements Linux, system ressource manager sur les environnements Windows)
-
Si l'accès au serveur n'est plus possible pour cause de saturation :
-
Cas des
[Déni de service sur les applications]- Désactiver les fonctionnalités non importantes posant problème, mais ne pas les supprimer (exemples : moteur de recherche, formulaire)
- Appliquer une limite de sessions au niveau des services web
- Utiliser la fonctionnalité de mise en cache
- Bloquer les requêtes par reconnaissance de robot (Challenge captcha dynamique ou challenge Javascript - JS)
- Réduire les durées de vie de suivi de connexions
- Optimiser la configuration des services web et de leurs composants (serveur web : Apache, Nginx, IIS; runtime : .Net JRE; Applicatif : tomcat, jboss, nodeJS)
- Statifier les contenus changeant peu, et dédier des serveurs à cet effet
- Redémarrer les services en cas de processus applicatif bloqué (mesurer les impacts au préalable)
-
-
(8) Serveurs de base de données
-
Cas des
[Déni de service sur les applications]-
Optimiser les ressources (calcul, mémoire, disque) et la configuration en cas de saturation
- Ajouter des instances en cas de cluster
-
Optimiser les ressources (calcul, mémoire, disque) et la configuration en cas de saturation
-
Cas des
Mesure 4 - Agir dans le périmètre des services dépendants
En cas de déni de service sur les services DNS :
Action 4.a : Agir sur les configurations du service DNS
-
(9) Service DNS
- Filtrer les requêtes DNS malformées ou invalides
- Filtrer sur les enregistrements DNS qui n'existent pas
- S'assurer que les fonctions inutilisées sont désactivées (par exemple : transfert de zone, rôle récursif exposé sur internet)
Action 4.b : Activer le CDN sur les attaques visant du contenu statique, si possible
En cas d'attaque sur les applications :
-
(10) CDN
-
Répartir la charge sur le contenu :
- Publier le contenu statique
- Mettre en cache le contenu dynamique (Attention aux effets de bord)
- Bloquer les requêtes par reconnaissance de robot (Challenge captcha dynamique ou challenge Javascript - JS)
-
Activer le service anti-DDoS du CDN :
- Effectuer une blacklist dans la configuration à partir d'éléments issus de la qualification (source, user-agent, entête spécifique, etc.)
-
Répartir la charge sur le contenu :
Attention: Le recours à un CDN doit prendre en compte les problématiques autour du RGPD et de la confidentialité des données (possible déchiffrement du flux)
Action 4.c : Agir sur les composants tiers
-
(11) Composants tiers
- Désactiver les composants tiers optionnels et non essentiels
Action 4.d : Activer un service anti-DDoS externe, si possible
-
Service de filtrage anti-DDoS externalisé dans le cloud
-
Activer le service externalisé par :
- Déroutement du trafic par des annonces BGP et mise en place d'un tunnel GRE
- Redirection du trafic via le protocole DNS
- Activer les fonctionnalités de défense en fonction du contexte et de la qualification
-
Activer le service externalisé par :
Attention: Pour la redirection du trafic via le protocole DNS :
- Prendre en compte le délai de propagation DNS et le certificat TLS à mettre sur le service externalisé
- Le recours à ce service doit prendre en compte les problématiques autour du RGPD et de la confidentialité des données (possible déchiffrement du flux)
- Cette méthode protège uniquement les attaques sur le nom de domaine et non sur les adresses IP
Préserver les traces
Mesure 5 - Préserver les traces
Action 5 : Préserver les traces des journaux d'équipements
- Exporter les logs des éléments cartographiés ou des captures manuelles du réseau
Pour soutenir la réponse à incident dans son objectif d'investigation, il faut prioritairement préserver les logs les plus anciens possibles.
Si les logs sont déjà exportés dans un SIEM ou un centralisateur de logs, il est alors inutile de les exporter et d'augmenter leur rétention sur les machines sources.
Attention: Une attaque par déni de service va augmenter la volumétrie de journaux. Une augmentation de la verbosité doit se faire au strict besoin de l'investigation tout en considérant le risque de saturation du stockage pouvant déclencher un nouveau déni de service.
Suite des actions
À la fin de ces actions d'endiguement, l'incident peut être potentiellement contenu. Cependant, une vigilance à travers la supervision doit être mise en œuvre, afin de détecter le retour d'un attaquant qui pourrait s'être adapté aux mesures de défense mises en œuvre.
Si l'incident n'est toujours pas contenu, la remédiation doit passer pour une réforme de l'architecture, de la contractualisation de service spécifique et de la formation des personnels.
De manière générale, un incident doit être géré jusqu'à son terme avec tous les corps de métier concernés : investigation forensique et remédiation par une équipe spécialisée, maintien d'activité, communication interne aux partenaires, dépôt de plainte et déclarations, etc.
Pour ce faire, il est conseillé de piloter la suite de la résolution de l'incident en cohérence avec les impacts identifiés et demander de l'aide :
-
Mettre en œuvre une gestion d'incident cyber pour piloter la résolution de l'incident.
- Voir les annexes Contacts et Déclarations.
De plus, si l'incident a un périmètre étendu sur le système d'information, qu'il a un impact fort et qu'il nécessite une résolution urgente :
-
Activer le dispositif de gestion de crise cyber de l'organisation pour piloter la résolution de l'incident et la continuité d'activité.
- Guide conseillé : Crise cyber, les clés d'une gestion opérationnelle et stratégique
Annexes
Liens utiles
Lors d'une lecture préparatoire de cette fiche ou pour aller plus loin dans la compréhension et la mise en œuvre des notions évoquées, certains documents annexes peuvent être utiles :
- Fiche réflexe - Déni de service réseau - Qualification
- Les essentiels - Les dénis de service distribués (DDoS)
- Comprendre et anticiper les attaques DDoS
- Crise d’origine cyber, les clés d’une gestion opérationnelle et stratégique
- Cyberattaques et remédiation
Définitions
Axes d'évaluation
- Périmètre : Le périmètre d'un incident désigne son étendue sur le système d'information et dans son administration.
- Impact : L'impact d'un incident désigne le niveau de perturbation et de dommage potentiel qu'il engendre pour l'organisation.
- Urgence : L'urgence d'un incident désigne la rapidité avec laquelle il faut réagir pour rétablir les activités essentielles impactées.
Compromission d'un compte de messagerie
Une compromission d'un compte de messagerie désigne un accès non autorisé à un compte de messagerie, par un attaquant. Ce dernier peut alors lire et envoyer des courriels à l'insu de l'utilisateur légitime du compte, et accéder à ses données.
Compromission système
Une compromission système est l'activité d'un code ou d'un acteur malveillant sur une machine du système d'information, résultant en sa prise de contrôle.
Faute de pouvoir qualifier précisément la prise de contrôle, dans de nombreux cas, toute activité adverse sur le système pouvant avoir donné lieu à une escalade de privilège est considérée comme une compromission. Une compromission entraîne généralement une forme de communication entre la machine compromise et un attaquant y exécutant des actions.
Degrés de gravité
- Anomalie courante (gravité faible) : Une anomalie courante est un incident de sécurité ne représentant pour l'instant pas de menace sérieuse pour la sécurité du système d'information et n'entraînant pas d'impact significatif sur l'activité métier. Elle nécessite tout de même d'être correctement qualifiée pour confirmer son faible degré de gravité.
- Incident mineur (gravité modérée) : Un incident mineur est un incident de sécurité représentant une menace limitée pour le système d'information et entraînant - ou risquant d'entraîner - un impact modéré sur l'activité métier.
- Incident majeur (gravité élevée) : Un incident majeur est un incident de sécurité représentant une menace sérieuse pour le système d'information et entraînant - ou risquant d'entraîner - un impact fort sur l'activité métier.
- Crise cyber (gravité critique) : Une crise cyber représente un incident de sécurité ayant un périmètre étendu sur le système d'information, un impact fort sur l'activité métier et nécessitant une résolution urgente.
Endiguer un incident
L'endiguement désigne l’ensemble des actions prises au début d’un incident de sécurité informatique destinées à en contenir l’ampleur. Elles n’ont généralement pas vocation à être prolongées durablement.
Fuite de données
Une fuite de données, également appelée violation de données, désigne un incident au cours duquel des informations confidentielles, sensibles ou protégées sont consultées, divulguées ou volées par une personne non autorisée. Cela peut concerner divers types de données, notamment des informations personnelles, financières, médicales, ou des secrets commerciaux.
Les fuites de données peuvent résulter de cyberattaques, comme le piratage ou le phishing, mais aussi d'erreurs humaines, telles que l'envoi d'informations à la mauvaise adresse e-mail ou la perte de dispositifs contenant des données sensibles. Les conséquences d'une fuite de données peuvent être graves, allant de pertes financières et d'atteintes à la réputation de l'entreprise à des problèmes juridiques et à la compromission de la vie privée des individus concernés.
Qualifier un incident
Qualifier un incident signifie :
- Confirmer qu'un incident de sécurité est bien en cours et si oui, déterminer précisément sa nature.
- Évaluer la gravité/priorité de l'incident en évaluant le périmètre affecté, l'impact potentiel sur le fonctionnement de l'organisation et l'urgence à le résoudre.
La qualification permettra de prendre des décisions éclairées sur la réponse à l'incident et d'allouer les ressources appropriées pour le résoudre.
Contacts
La gestion d’un incident cyber implique de faire appel à des équipes spécialisées au sein de CERT/CSIRT, qui appuieront les équipes internes dans la réalisation de leurs actions de défense.
| Qui ? | Comment ? | Pour qui ? |
|---|---|---|
| CERT/CSIRT interne de l'organisation | Se référer aux procédures internes. | Pour les organisation disposant d'une équipe de réponse à incident interne. |
| CERT/CSIRT externe en prestation de réponse à incident | https://www.cybermalveillance.gouv.fr/diagnostic/accueil https://cyber.gouv.fr/prestataires-de-reponse-aux-incidents-de-securite-pris |
Pour les petites organisations : consulter le registre des prestataires spécialisés sur Cybermalveillance Pour les organisations opérant un système d’information complexe : faire appel à un Prestataire qualifié de Réponse à Incidents de Sécurité (PRIS) |
| CSIRT régional | https://www.cert.ssi.gouv.fr/csirt/csirt-regionaux | Pour les organisations de taille intermédiaire : collectivités territoriales, PME, ETI ou associations |
| CERT sectoriel | https://www.cert-aviation.fr https://www.m-cert.fr https://esante.gouv.fr/produits-services/cert-sante |
Pour les organisations du secteur de l'aviation, maritime ou santé |
| CERT-FR | Consulter la section Contacter le CERT-FR | Pour les administrations et les opérateurs d’importance vitale et de services essentiels |
De plus, pour les incidents complexes, une aide externe est également recommandée pour :
- Gérer la crise
- Gérer la communication interne et externe
- Augmenter les ressources humaines et capacitaires de reconstruction de votre direction informatique
Pour faciliter la mobilisation de tous ces acteurs, il est conseillé de s’appuyer sur des annuaires tenus à jour en amont et accessibles même en cas d'indisponibilité du système d'information.
Déclarations
Conjointement à la résolution de l'incident, des déclarations doivent être effectuées :
| Qui ? | Comment ? | Pourquoi ? |
|---|---|---|
| Assureurs | Notifier son assurance cyber permet de démarrer la prise en compte de la couverture et d'identifier des prestataires que l’assureur pourra recommander ou mandater. | |
| ANSSI | https://www.cert.ssi.gouv.fr/contact/ https://cyber.gouv.fr/notifications-reglementaires |
L’administration, les opérateurs d’importance vitale et de services essentiels, et toute organisation impliquant des informations classifiées, doivent déclarer leurs incidents à l'ANSSI. |
| Dépôt de plainte | https://www.francenum.gouv.fr/guides-et-conseils/protection-contre-les-risques/cybersecurite/comment-porter-plainte-en-cas-de | Déposer plainte permet de déclencher une enquête et de dégager votre responsabilité en cas de propagation de l’attaque à d’autres victimes. |
| CNIL | https://www.cnil.fr/fr/notifier-une-violation-de-donnees-personnelles | Les incidents affectant des données personnelles doivent faire l’objet de déclaration à la CNIL dans un délai de 72 heures. En cas de doute, il faut faire une pré-déclaration précisant avoir subi une potentielle compromission même si aucune exfiltration de données n'a été confirmée. |
| Autres autorités | Une organisation d'un domaine réglementé (finance, santé, etc.) est astreinte à des obligations de déclaration spécifiques. Dans le doute, consulter le service juridique. |
Préparation
En prévention d'un incident, une fiche réflexe sera d'autant plus efficace si elle a pu être préparée en amont, contextualisée et traduite en une procédure interne et actionnable immédiatement à son système d'information. Dans une situation d’urgence, elle augmentera la rapidité de la réponse, minimisera les erreurs de manipulation et permettra à une personne d'astreinte moins expérimentée de mener ces actions.
Il est également conseillé d'imprimer les fiches réflexes afin qu'elles restent disponibles en cas d'indisponibilité du système d'information. Il en va de même pour les autres documents utiles, comme la notice d'aide au dépôt de plainte ou votre annuaire de contacts.
Contacter le CERT-FR
Attention: Quand vous effectuez un signalement auprès du CERT-FR, un numéro de référence vous est attribué. Pensez à rappeler ce numéro quand vous nous recontactez, ou dans l'entête de vos messages afin de simplifier le suivi du cas.
Par Téléphone
Le CERT-FR est joignable 7J/7, 24H/24:
- depuis la France métropolitaine au 3218 (service gratuit + prix d’un appel) ou 09 70 83 32 18
- depuis certaines collectivités territoriales situées en Outre-mer ou depuis l’étranger au +33 9 70 83 32 18
Par Internet
- mèl:
cert-fr@ssi.gouv.fr - site: https://cert.ssi.gouv.fr/contact/
Clé PGP du CERT-FR
Pour vérifier l’intégrité des informations fournies ci-dessous, veuillez contacter le CERT-FR.
Identifiant de la clé : 0x1B45CF2A
Empreinte de la clé : 7F4C 8FA6 A356 D1CC 2E5C AB09 5416 33B8 1B45 CF2A
Télécharger la clé publique: https://cert.ssi.gouv.fr/uploads/public_key_2024.asc
Licence
Ce document est dérivé des travaux du GT Fiches Réflexes de remédiation de l'InterCERT FRANCE
Les documents originaux peuvent être consultés sur le site de l'InterCERT-France (https://www.intercert-france.fr/publications/fiches-reflexes/).
Le présent document est publié sous licence CC BY-NC-SA 4.0.